Week 2 Notes — Arrays
Saturday Jan. 9 to Friday, Jan. 15
Links
- Return to CS50x Cohort home page
- Harvard CS50x week 2 page
Week 2 Video (duration 2:24:58)
Complete your reading Chapter 1 of Kernighan and Ritchie in parallel with watching this week’s lecture. Malan is using different examples than Kernighan and Ritchie, but you are going to see a lot of parallels in the exposition nonetheless. Then, when you get to Chapter 2 of Kernighan and Ritchie, you will have enough examples under your belt to appreciate the grammar of C. A programming language is a grammar, no more and no less. As the compiler recognizes statements that conform to the grammar, it produces some machine code that goes into the executable file — mario.c is turned into mario. This actually involves four steps(!) as you’ll hear in this lecture. If the compiler encounters code that doesn’t match C’s grammar, then it produces as many helpful errors as it can and terminates without creating an executable. Computers are terrible at making correct inferences when there are elisions or minor mistakes. If your program doesn’t conform to C’s grammar, mostly it will just tell you (in gory detail), where it hit the conforming program lines. It certainly won’t make a reasonable inference of what you meant and try to continue.
This is a good moment to mention something Malan deliberately glossed over in Week 1. When you type make mario, you aren’t actually running the compiler. You are running make. In turn, make runs the compiler, which nowadays is no longer cc on most systems (that is what it is called in Kernighan and Ritchie’s book), but a newer program called clang which is short for “C language compiler.” Although clang does the same thing as cc, it does it in a very versatile way that allows for support of the ridiculously large variety of modern computer systems and even other computer languages. Running clang has so many options that it is very useful to let make run it for you rather than running it directly. On the other hand, knowing what make and clang are actually doing can be useful when trying to understand the error messages that will inevitably be spewed by make, and so that is Malan’s first topic.
- 0:02:30 Malan uses
makeand the arguments it is passing toclangto introduce the idea of program arguments. Then he talks aboutclangand the linker needing to be passed the argument-lcs50in order to find the cs50 chunk of machine code. The linker takes multiple chunks of machine code and assembles them into a single executable program. The compiler is actually only producing one of the chunks when you domake mario. The other chunks were produced by people that created the cs50 library (as one example of the many people who contribute chunks of code) and the cs50 library was preinstalled onto your Ubuntu system when the IDE was installed. Malan enumerates the steps that are occurring as: (1) preprocessing, (2) compiling which actually produces assembly code, (3) assembling which actually produces the machine code, and finally (4) linking. It is impressive that Malan is revealing all of these details to a class of newbies. If knowing about the four steps seems like a bit much, it is ok to just consider this to be exposure rather than something you have to solidly understand. The real point is that any of steps (1), (2), and (4) can fail, and when they do it helps to have a mental picture of what the steps are. It is so rare for step (3) to fail that you don’t have to contemplate that possibility. Questions by students at end allowed Malan to reveal yet more things (that he necessarily glossed over because he has already spent 23 minutes without getting any closer to today’s nominal topic, arrays in C). - 0:23:00 Debugging using printf (accck!). It is an extremely bad habit to use printf for debugging. Pay far more attention to the next tool he shows you, which in this environment is called debug50. He shows how to set breakpoints. The graphical icons in the upper right of ide50 that appear when a breakpoint is hit are controlling debug50, which is a wrapper around gdb, the industry-standard debugger for C. He closes the debug50 discussion by encouraging you to learn to use the debugger rather than relying on printf. His final debugging method is rubber-duck debugging, which is equivalent to saying that “two heads are better than one, even if one is a cabbage.” The idea is that just verbalizing your issue to the rubber duck often reveals a misconception or the next thing to try.
- 0:50:00 The sizes of bool, char, double, etc., in bytes. RAM vs. long-term storage. How data is stored in RAM. Using the program
scores.cto illustrate an array to hold several scores back-to-back (contiguously) in memory. Along the way Malan also introduced the const qualifier. He also showed how arrays are passed to functions. He hasn’t explained how to dynamically change the size of an array. Wait on that. Pretend you always know the size of the array in advance for now. The reason is that dynamically-sized arrays requires more control over memory than you have yet, because the amount of memory that needs to be allocated isn’t decided at compile time. The question and answer at 1:20:00 gets at this issue. - 1:23:40 ASCII strings as null-terminated arrays, read one
charat a time, illustrated by a programhi.c. He even showed that you can go far beyond the end of a string array. What is out there is unpredictable. He is just poking around in computer memory. Accidentally poking in places you really didn’t mean to poke is a common and difficult-to-track-down cause of program errors and crashes. Illustrating how the null-termination is used by a programstring.cis next. A pleasant fact is that he is already getting into performance. Notice thatstrlen(s)is repeatedly evaluated in his example of poor programming, and if the string is long that could be an unnecessarily large use of the computer’s power. - 1:48:00 Arrays of strings, and accessing the individual characters as if they are a two-dimensional array:
words[1][2]. Changing strings to upper-case:uppercase.c. Introducing the manual pages (to look upislower,toupper, and any other function that is in the C libraries). There is an enormous amount of functionality in the standard C libraries. Malan is encouraging you to explore and use that functionality when writing your solutions to this week’s problems. - 2:01:30 Inputs are actually allowed to
main. This is the actual declaration for main:int main(int argc, string argv[]). We have been getting away withint main(void)because we have been ignoring — e.g., not using — the command-line arguments.argv[0]points to the program name (as it was typed to invoke the program in the shell).argv[1]points to the first argument after the program name (if there is one). We have always declaredmainto return anint. What utility does this have? How can you see what a program has returned (which is distinct from what it has written to stdout). He shows you theecho $?shell gibberish to see what the previously run program returned. We will get more into this gibberish later. It isn’t as bad as it looks. - 2:14:20 Introducing two applications of this all this string- and character-oriented arcanae, specifically this week’s problem topics: readability and cryptography. Final couple of minutes: “Be sure to drink your Ovaltine.”
After you have done this week’s problem set is a good time to read Chapter 2 of Kernighan and Ritchie. The idea of Chapter 2 is to start thinking of C as a rigorously-defined grammar. You’ll still mostly think in terms of the examples Malan has shown you and that you have written, but knowing that there is a grammar and that all the examples you have seen conform to a grammar is perhaps the first beautiful thing that belongs to the subject of computer science. Practically-speaking, knowing what some of the grammars elements are — e.g., statement, expression, declaration, constant, etc. — will help you interpret compiler error messages.
Problem Set 2
Problem Set 2 is to write two programs. One is readability.c. The other is either caesar.c or substitution.c, both of which are very simple examples from the field of cryptography.
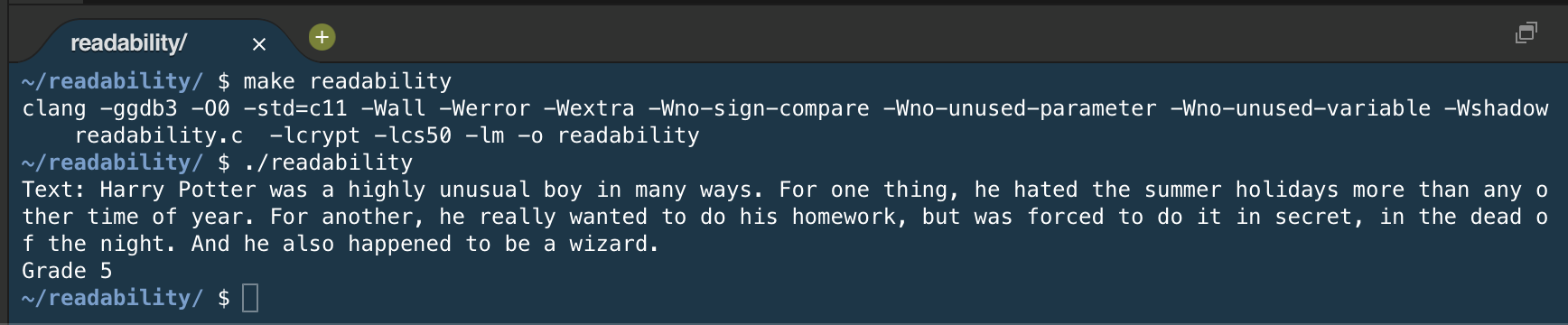
My readability.c output for the Harry Potter text:
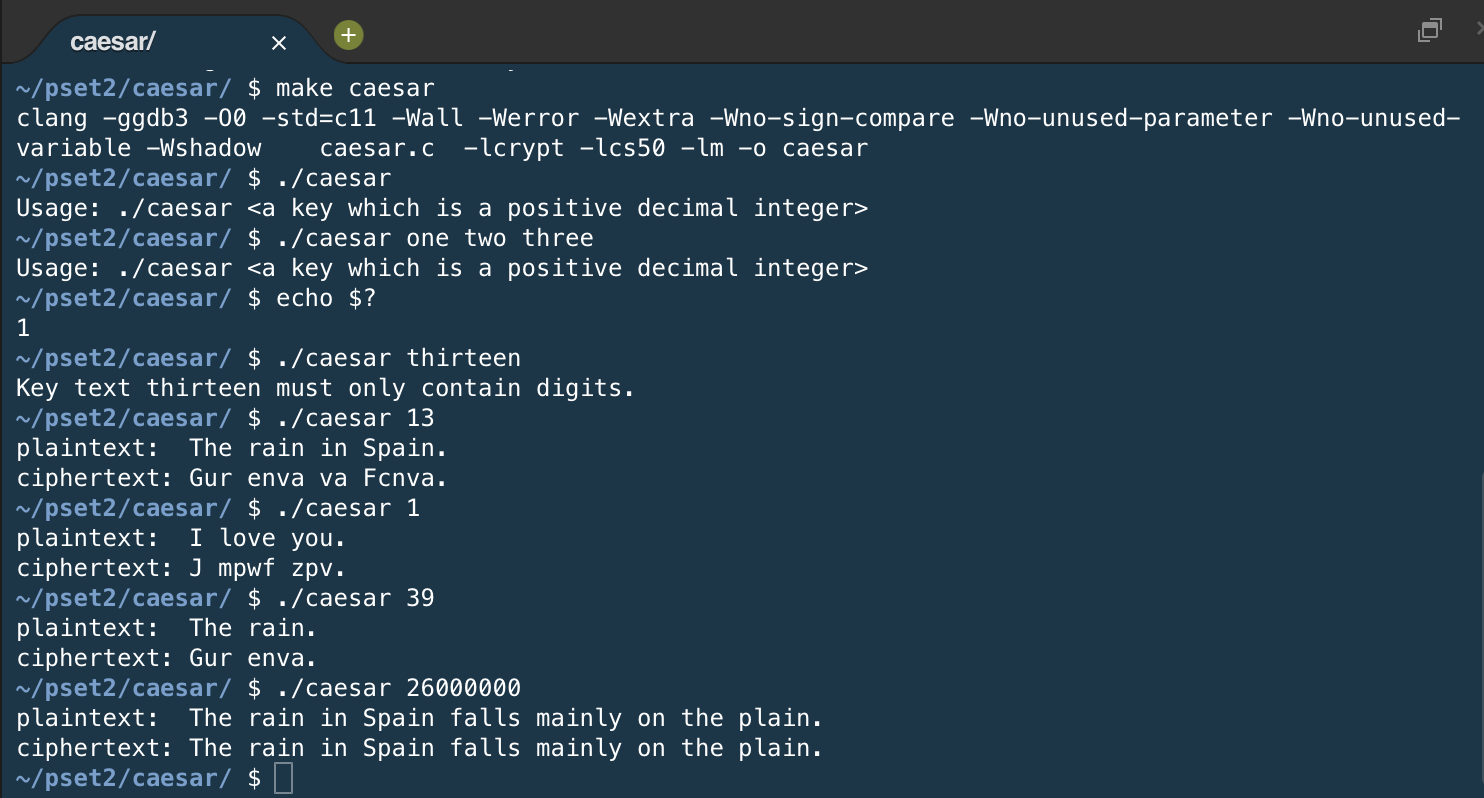
My caesar.c output for miscellaneous inputs:
Some comments on caesar.c
First, here is a cheesy, fast workaround
You don’t really need to make a copy of plaintext to hold the ciphertext. You can work through plaintext one character at a time, encipher it one character at a time, and print the enciphered character one at a time. No copy ever needed!
Second, here is the real answer that does not dodge your question
The fundamental thing to understand is what does
int[] some_numbers = {7, 5, 3, 4, 2};
actually do?
The compiler notes that you have five ints requiring four bytes each, and that the initializer lists five of them, and therefore 20 bytes of memory will have to be reserved.
some_numbers is not all the items in memory, nor is it even the first item in the memory. It is called a pointer. It just says where the first item is.
When you later refer to some_numbers[0], that gets the contents of the first location. If you use the jargon that some_numbers is a “reference” then some_numbers[0] “dereferences” the pointer.
Imagine you knew that Skippy was 10 items down aisle four in a Von’s. shelf_stock[4][10] gets you Skippy. But shelf_stock itself is a location. It is not to be confused with either shelf_stock[0][0] which might have Cheerios, or of all of the shelf stock. shelf_stock is just a starting point.
Next, what does
int[] sorted_numbers = some_numbers;
do?
It does not reserve 20 new bytes of memory! It just makes a copy of some_numbers which isn’t what you wanted! To use the Von’s example, the new copy you’ve now got if you did
product[] other_shelf_stock = shelf_stock;
in other_shelf_stock refers to the exact same starting location in the same grocery store. If the store manager decides that Adam’s peanut butter goes at shelf_stock[4][10] then Adam’s peanut butter will now also be at other_shelf_stock[4][10]
C is a pass-by-reference language. Rarely do copies get made. When you want an actual copy (because you are opening another Von’s and they might not have the same store layout, but perhaps you want to start with the same layout), you have to do what is called a deep copy. You don’t yet have the tools yet to do a deep copy. You will need the malloc() function and the memcpy() function, and I suspect both of those are coming next week.
C is an outrageously high-performance language. You can only get higher performance by hand coding the assembler yourself and human time is so costly compared to computer time that almost nobody does that anymore. C’s syntax rarely implies something expensive (like making a deep copy) when it could imply something cheap (like making a new reference reference from an existing reference).
In coming weeks watch for the buzzwords:
pass by reference pass by value pointer dereference deep copy
I’m sure Malan doesn’t intend to leave you in the dark about this for long.