Week 3 Notes — Algorithms
Saturday, Jan. 16 to Friday, Jan. 22
Links
- Return to CS50x Cohort home page
- Harvard CS50x week 3 page
Week 3 Video (duration 2:25:25)
Malan opens with a discussion of algorithmic cost. The number of times a loop is executed is often an appropriate metric for the cost of a routine, but rest assured, it is far from the only metric or the only important one. Assessing algorithmic cost is our second topic from the subject of computer science. (The first that we have only scratched was the grammar of a computer language.) The main job in this course is to learn meat-and-potatoes programming techniques (which aren’t really computer science, any more than word processing is literature). Why introduce more computer science? Well pragmatically, because it is very easy to write horribly inefficient code, and some time spent on the topic of algorithmic cost can help you think about how to make your code efficient. On the other hand, code correctness is even more important than efficiency, so try to write a correct algorithm first, including tests that it is correct, and then use the correct algorithm and the tests of it as cross-checks on whatever more efficient algorithms you later come up with. Worrying about algorithmic efficiency too early when solving a particular problem is as common as failing to worry about it at all, and it even a name, “premature optimization.”
- 0:04:20 Malan begins a discussion of algorithms with a review of how a computer searches an array. Unlike a human, a computer doesn’t have a birds-eye view of an array. It searches one location at a time. Just for clarity, note that a location might be eight bytes if it is a 64-bit computer and it is doubles or long ints that are being examined. A 64-bit computer, as most are nowadays, is a 64-bit computer precisely because it can work with 64 bits at a time. How many bits a computer processor can process at once is known as its “word” size. Next is big-O notation: O(1), O(log n), O(n), O(n log n), etc. On the matter of n and n/2 being different as you zoom out, Malan is oversimplifying or even mis-spoke: n and n/2 will look equally divergent at any scale. However log n indeed diverges more and more from either n or n/2 as you zoom out. Furthermore, the list of functions he gave when illustrating big O notation — O(1), O(log n), O(n), O(n log n), O(n2) — are specifically chosen because those diverge from each other more and more obviously as you zoom out, and because they often come up in the analysis of algorithms. By contrast n and n/2 are always in the same ratio — 1/2 — regardless of how large n is. Other functions — like sqrt(n) and other fractional powers like the cube root of n — are additional examples of functions that look more and more different from any of those in Malan’s list at large scales. However those are not in his list because they rarely show up in the analysis of computer algorithms. To get precise about this stuff, you have to use limits (a foundations-of-calculus subject) and for good reason Malan doesn’t want to drag the class into that — if you know limits you could take a look at various definitions of the Big-O notation, and there are many. Malan is hoping people can at least partially intuit that n and n/2 are “less different” to each other than to log n without studying limits. Malan says that just as he is using O to denote upper bounds, he will use Ω to denote lower bounds. Linear search is O(n). Binary search is O(log n), but it requires the list to be sorted.
- 0:32:00 Malan implements a linear search through a list of numbers
number.cand uses the exercise to emphasize return values. Then he implements string searchnames.cthat makes heavy use of C’sstrcmpfunction. He emphasizes thatstrcmpuses the ASCII value of a character to alphabetize.strcmpreturns 0 if two strings have exactly the same ASCII characters. It would be good to stop the video and locate some documentation forstrcmpas a way of starting to become familiar with how C library functions are documented and what others are available. Whatever documentation you decide to rely on should allow you to browse all the other functions instring.h. - 0:51:30 Some new C syntax for this week is the next subject, and the two new concepts are
typedefandstruct. Malan introduces both of these simultaneously even though you can use a typedef on any type, new or old. For example,typedef int num;would allow you to start referring to the int type as num in your code. Synonyms for fundamental types aren’t very interesting (at least in C which is very permissive on type checking and casting), so typedef comes into its own when it is used with a new and complicated combination such as when you use typedef in conjunction with defining a struct. His example istypedef struct { string name; string number; } person;illustrated inphonebook.c. Malan didn’t say it, butnameandnumberare known as “members” of thepersonstruct. The Q&A started into the idea of creating your own header files and that the typedef might reside in a header file rather than in the same file asmain. Malan said that he will be getting to this in a later week. - 1:14:45 Binary search is fast. However, as already mentioned, it requires a sorted list, and it’s now time to work more on sorting. Malan discusses premature optimization and emphasizes that human time (spent writing and debugging code) is valuable too. Next he discusses two practical algorithms for sorting (with perhaps painfully pedantic sorting demos by his assistant). The first is the simplest and is called “selection sort.” However, selection sort is O(n2). Next is bubble sort which is also O(n2). Malan spends a fair amount of time discussing lower bounds and this is frankly not that important. Because they depend on the specific circumstances, lower bounds are generally misleading. There is usually no reason to expect that a routine will get lucky enough of the time to be working near its lower bound, and in general upper bounds are much more representative of a routine’s costs — and wouldn’t you rather know about the worst case anyway (unless you have reason to believe that it is highly non-representative). Malan points out that O(n2) is bad (1 thousand elements in an array will require order 1 million comparisons — 1 million elements will require order 1 trillion comparisons). Both routines we have seen so far are O(n2). Surprisingly, this can be drastically improved, and that is the next subject.
- 1:55:30 Malan starts into merge sort, but first he is going to define recursion, because recursion is probably the most straightforward way to implement merge sort. The key thing about merge sort is that you subdivide the problem into two halves at each step. Shockingly, this shortens the number of comparisons that need to be done to O(n log n). He is introducing recursion now because recursion is the most straightforward way of implementing the subdivision. Can you think of a recursive way of implementing selection sort? Yes. Does recursion make selection sort less than O(n2)? No. So my point is that it is not recursion that shortened the time. It is the fundamentally new strategy of dividing the original list, sorting the smaller lists, and then merging them. After more sorting demos by his assistant, Malan introduces Θ notation. Again, in practice and in general the only one to seriously worry about is the upper bound, Big-O, unless you aware of special circumstances, an example of which I will give below. The last minute or so is a very nice short video showing all three routines racing to sort the same array. Merge sort leaves selection sort and bubble sort in the dust.
When I said that lower bounds are generally misleading or unimportant, I alluded to specific circumstances. Here is an example: suppose that you are given a list that was sorted, but then exactly one item has been prepended to the list. Now that is a very specific circumstance — but one that you can easily imagine occurring in a software system, such as software for a business that needs to consult its customer database far more often than it adds or removes customers from the database — and you can see that if you do just one pass of the bubble sort, you will put the new item in the correct position and that after this new item has bubbled to its position then nothing more needs to be done because by assumption all the other items were already sorted. The upshot is that if you know that you are going to re-sort a list each time an item is added to it, then you might be ok with bubble sort even though its upper bound is O(n2) because this special circumstance is going to put the routine near its lower bound.
Although structs are a bit fancy to already be introducing in your second week of C programming (and indeed one of the student’s questions when structs were introduced was essentially, “I’m overwhelmed by all the C syntax, what now?”), it is worthwhile, and this is the only new C syntax for this week. For motivation, structs have some (but most definitely not all!) of the behavior of objects, and objects are an enormously powerful and popular programming paradigm. This is not the time to go investigate “object-oriented programming.” I’m mentioning it just for motivation and to describe the programming language landscape. What you are learning right now by learning C is called “procedural programming” and structs give you just a taste of how objects can group data and behavior.
Also, since you are studying C you might like to know that the C++ extension of C grafts objects onto C — and does it in a bad way! — but C was so popular that C++ caught on for a decade or two until object-oriented languages that you can be much more productive in caught on (especially influential have been Smalltalk, Objective-C, Java, and Swift). The features of the influential object-oriented languages were also grafted onto C++ and so C++ is now a kitchen sink. Malan is not going to go into any of that. He will stick with the 1999 version of ANSI C.
Just for completeness, I’ll mention that yet another powerful paradigm is called “functional programming” and very many things in a functional language are accomplished by passing functions themselves around as if they were variables. Maybe if you want all the elements of an array to add themselves up, you somehow pass the array the function add. So array somehow operates on add instead of add operating on array. You could also pass array the function multiply and get the product of the elements. At present, you want to just hammer on procedural programming until your main limitation in banging out lines of code is simply how fast you can accurately type them.
Problem Set 3
This week’s problem set consists of two programs, plurality.c and one of either runoff.c or tideman.c.
This first program is really quite easy because most of the code is provided. You just fill in the implementation for two functions. I see no reason to use any of the fancy search or sort strategies you have learned. Just use linear search. The only thing that makes it tricky is that you will be accessing the members (name and votes) of the candidate struct, and this involves syntax that you have only just been shown.
Interestingly, the function that prints the winner doesn’t take any arguments. So how can it
compute which candidate won? This is an example of what is called “scope” or “visibility.” In particular,
candidates is declared outside of main, and it has “global” scope. Any code that follows the declaration can use it. Declarations that occur inside curly braces are generally only visible to code within those curly braces. That is “local” scope.
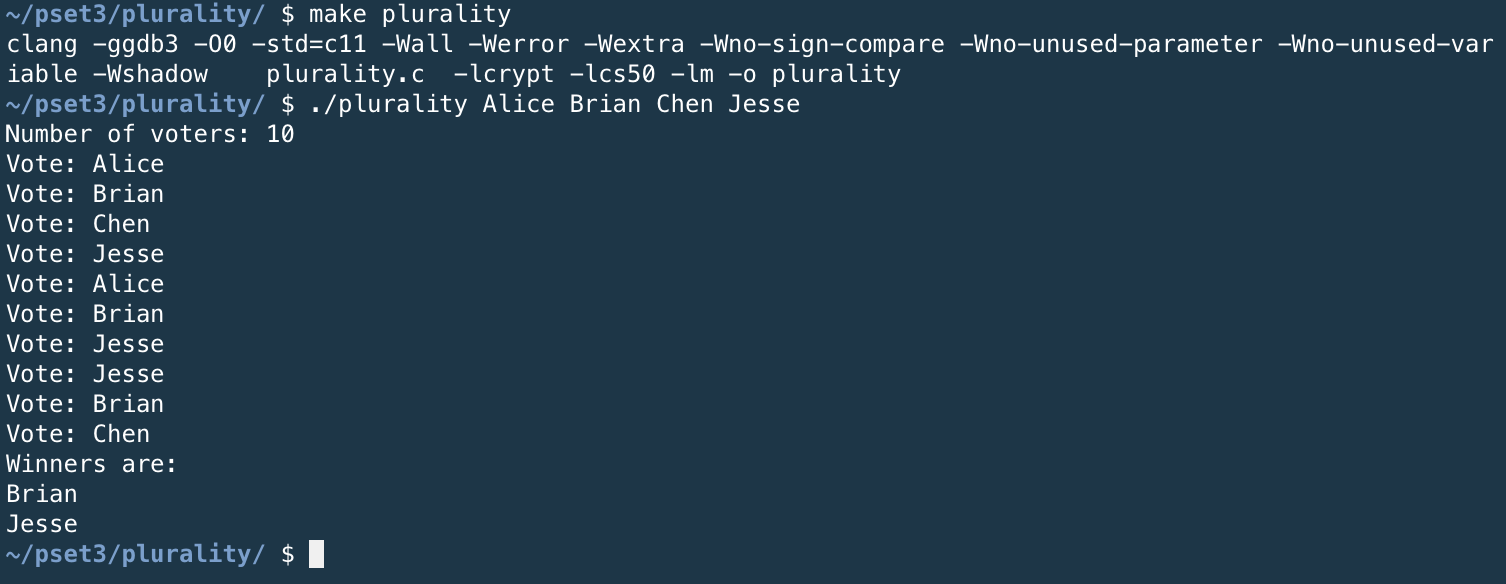
My plurality.c output:
For runoff.c we have run into the first program where I’d say it is a little hard to figure out exactly what is being asked (rather than perhaps hard implement what is being asked). I copied all the comments in the directions into the code so that I could repeatedly refer to what was being asked.
This program also used a lot of variables with global scope as a way of sharing information between functions.
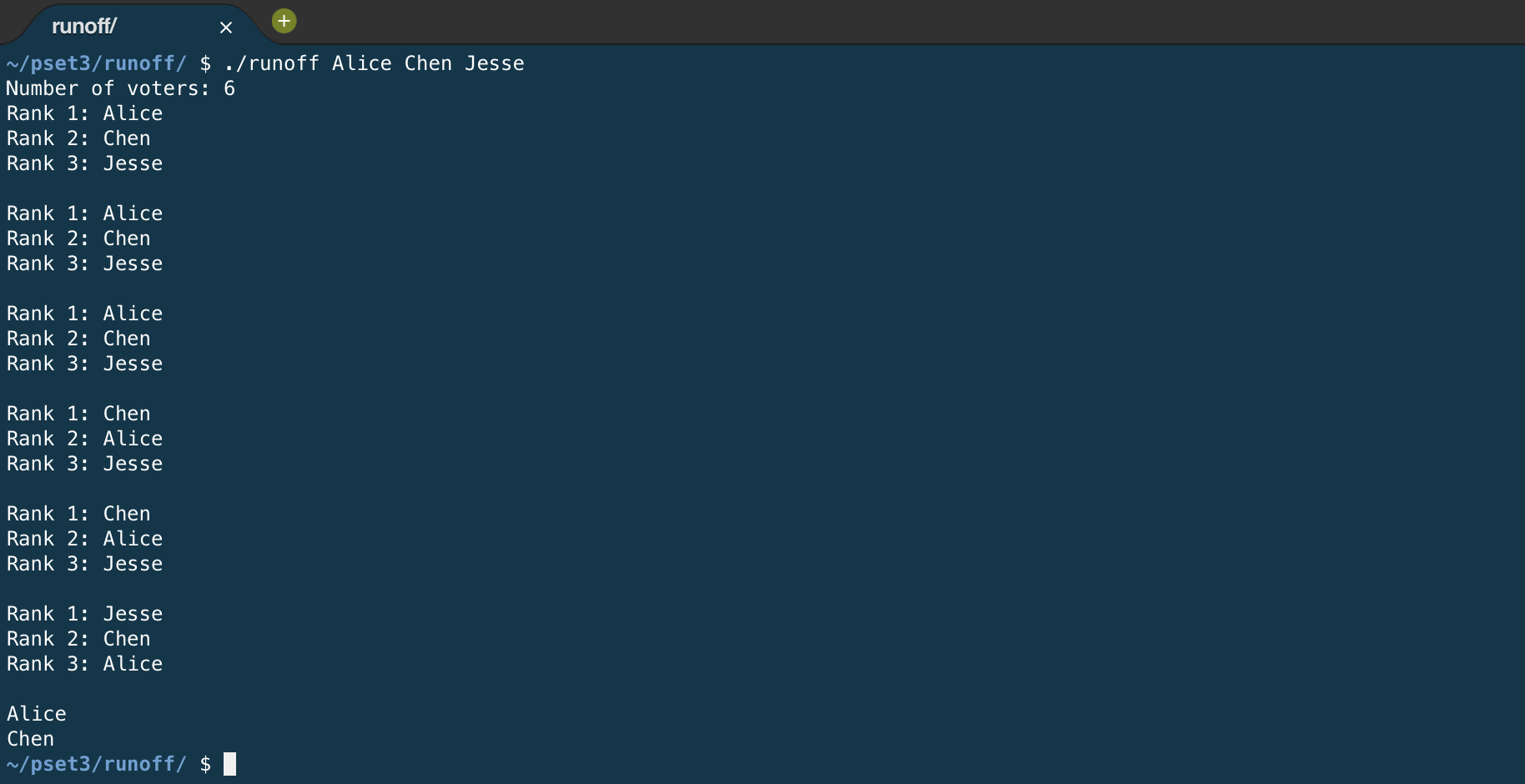
My runoff.c output for a case where the last voter’s second-ranked choice caused a tie to occur: