Week 5 Notes — Data Structures
Saturday, Jan. 30 to Friday, Feb. 19
Links
- Return to CS50x Cohort home page
- Harvard CS50x week 5 page
Week 5 Video (duration 2:26:39)
- 0:01:30 How to dynamically enlarge arrays by utilizing a data structure that is called a linked list. Malan argues that inserting elements into an array one at a time is O(n). (There is a way to avoid this that is very often better than linked lists, but Malan is just bringing up arrays only to segue to linked lists, so he immediately goes to that without mentioning any other solutions.) At 0:32:50 he introduces syntactic sugar
(*n).nextcan be written asn->next. The way he is appending items to the linked list is horrible (it is plainly O(n) because he has described walking through the list to the last node to append one more node). At 0:41:00 as part of Q&A Malan reveals the strategy that inserting at the beginning of the list is O(1). - 0:43:00
list.cusing arrays andrealloc(). I am not sure that he is usingrealloc()quite defensively enough, although he discusses thatrealloc()can return the same address. Be careful not to free the old list if the new list is the same as the old one. - 1:00:45
list.cusing a linked list. Keeping a list sorted as new nodes are inserted. - 1:19:45 Tree structures and binary search trees. Insertion in a sorted tree is O(log n). Binary search trees can get long and stringy. They may need to be rebalanced. In this course you won’t have to do that.
- 1:42:30 Hashes and hash tables. Hash collisions. Malan attempts to distinguish between O(n) “asymptotically” vs. in the real world. His argument is that his contact database only has a few hundred contacts, most likely, and so if you divide into 26 (or 26 * 26) buckets, no bucket will have very many contacts.
- 2:03:00 Introducing “Tries” short for “retrievals” which are trees of arrays. It only depends on the length of the name. Lookups are O(1). However, this data structure is very memory-hungry. Most of the entries at the leaves of the tree are empty.
- 2:12:00 FIFO queue (queue and dequeue) and LIFO stack (push and pop). Many people (including the authors of Python’s queue package) call both of these queues and are careful to specify which type you. Dictionaries (associates keys with values). A dictionary cannot handle two values with the same key. You could of course make the value an array, and then you could put many of whatever you are inserting into the dictionary into each value.
Problem Set 5
Just one problem this week, and that is to implement all the functions in dictionary.c which are used by the program speller.
I chose a hash table size of UINT16_MAX which is 65536 buckets. The larger dictionary has 143088 words, so there will be a little more than two words per bucket on average. It seems my hash function is a good one (it distributes the words pretty uniformly in the buckets) because my check function is a little faster than the staff’s (0.01 vs 0.02 time spent in check on texts/lalaland.txt, and times in load, size, and unload were the same).
My speller output on the Constitution:
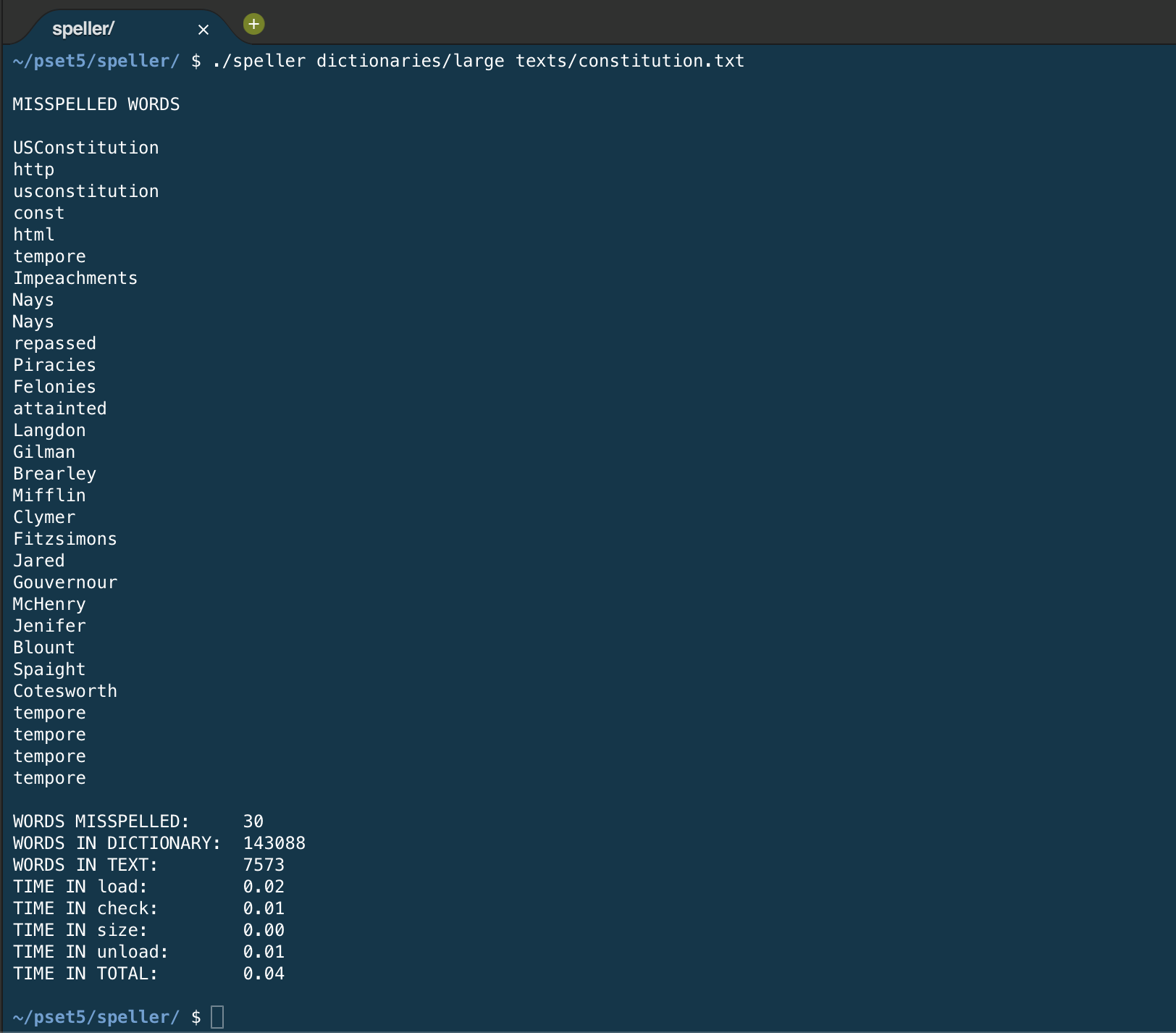
You can see that the 143088-word dictionary is a bit lacking because some of these words — like “felonies,” which is the perfectly legitimate plural of “felony”) ought not to be marked as mis-spellings. The staff’s program gives identical results.